NEURAL
ORCHESTRATION.
I architect the Central Nervous System of your business. Autonomous Agents and Self-Healing Workflows that bridge the gap between your Raw Data and AI Models.












1.0 // The Automation Stack
COGNITIVE PIPELINES
01 // VECTOR INGESTION
Tech: Pinecone, OpenAI, Vectors
AGENTIC LOGIC
02 // PROTOCOL-BASED AGENTS
Tech: LangChain, Tools, JSON
SYSTEM INTEGRATION
03 // DYNAMIC LOGGING
Tech: Google APIs, Webhooks, HTTP
2.0 // Case Studies
PROJECT SYNAPSE
THE LIVING KNOWLEDGE BASE
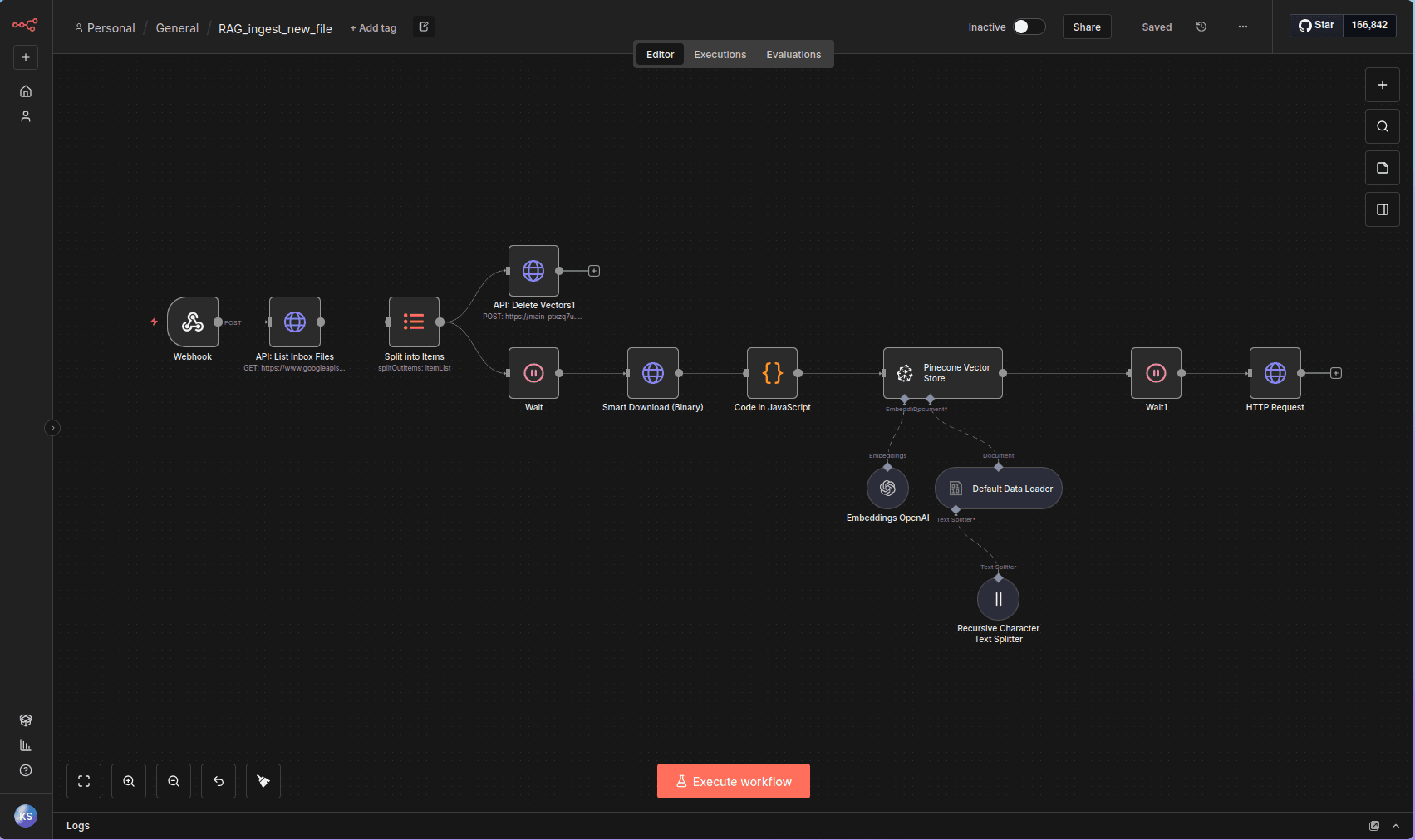
The Challenge: AI models are useless if their data is old. The client needed a way to "teach" the AI new policies instantly by just dropping a PDF into a folder.
The Architecture: A webhook-triggered flow that lists files from a Google Drive Inbox. Custom JS nodes convert Docs to text while handling PDFs as binaries. Before upserting, we delete old vectors to prevent "Ghost Data".
"I don't just copy files. I manage Vector Lifecycles."
if (!item.binary && item.json.data) { // Handle Google Doc Export const textContent = item.json.data; item.binary = {; data: Buffer.from(textContent).toString('base64'), mimeType: 'text/plain', fileName: original.name + '.txt' }; } else { // Handle Native Binary (PDF/IMG) item.binary.data.fileName = original.name; } return $input.all();
PROJECT NEXUS
THE OMNI-AGENT BACKEND
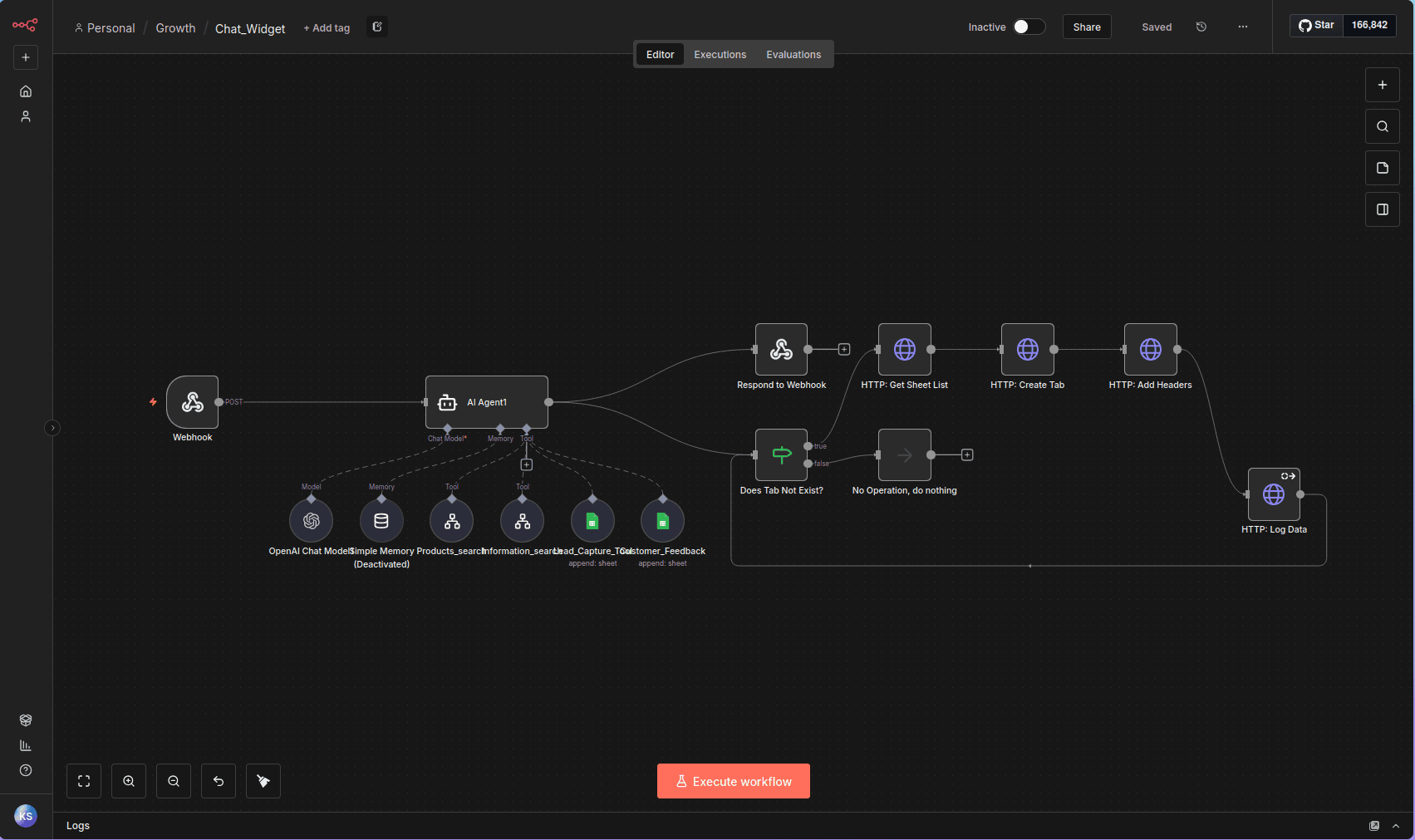
The Challenge: Standard chatbots hallucinate. The client needed a bot that acted like a trained Sales Rep.
The Architecture: A LangChain Agent with 4 distinct Protocols (Consult, Product Search, Info, Closing). The agent autonomously decides when to query the Inventory DB or capture lead data into Sheets.
- Protocol Enforcement: Strict System Prompts prevent off-topic chatter.
- Tool Orchestration: Autonomous JSON-based tool calling.
- Hybrid Output: Returns Text + UI JSON for frontend rendering.
> ACTION: Generating Proposal (GPT-4o)
> STATUS: DRAFTING...
PROJECT UPWORK-AI
THE FREELANCE AUTOPILOT
The Challenge: The best freelance jobs are gone in minutes. Manually refreshing feeds is a losing game. I needed a system to beat standard notifications and draft 6-figure proposals instantly.
The Architecture: A real-time monitor that bypasses RSS for direct GraphQL access. It filters for high-ticket clients (Payment Verified, Spend > $500), then triggers a "Chief Engineer" agent to estimate the work and a "Sales Agent" to write the pitch.
- Zero Latency: Detects jobs < 10 seconds after posting via GraphQL.
- Smart Estimation: AI analyzes requirements to produce a line-item hour estimate automatically.
- Sniper Mode: Sends instant Telegram alerts with "Apply Now" links for 95%+ matches.
PROJECT DATA-SALVAGE
THE OCR RECOVERY ENGINE
The Challenge: A client sat on 10,000+ scanned legacy contracts. They were just images—"Dark Data" invisible to search and unreadable by LLMs. Standard tools crashed on the corrupted file headers.
The Architecture: A brutalist Python pipeline. I use PyMuPDF for bit-level surgery to fix broken XREF tables, then pipe the raw image streams into Tesseract to reconstruct a hidden text layer.
- Deep Repair: Rebuilds PDF binary structures that Adobe Reader rejects.
- LLM Ready: Converts dead pixels into clean, tokenizable JSON/Text.
- Metadata Enrichment: Automatically extracts authors, dates, and titles for DB indexing.
1 0 obj<</Type/Catalog/Pages 2 0 R>>endobj
3 0 obj<</Type/Page/MediaBox[0 0 595 842]
/Contents 4 0 R/Resources<</Font<</F1
5 0 R>>>>>>endobj 4 0 obj
<</Length 44>>stream
BT /F1 12 Tf 100 700 Td (H3ll0 W0rld) Tj ET
NO_EOF_MARKER_FOUND
>> CORRUPT_XREF_TABLE_AT_OFFSET_1024
>> UNREADABLE_BYTE_SEQUENCE...
"status": "REPAIRED",
"meta": {
"author": "J. Doe",
"pages": 14,
"has_ocr": true
},
"content_layer": "Reconstructed via Tesseract 5.0..."
}
> INJECTED: Hidden Text Layer
<w:body>ERROR_EOF
<w:p>
<w:r>
<w:t>Contract ID: #992</w:BROKEN>
</w:r>
<ERROR_TAG_MISMATCH>
</w:document>
**Status:** Active
**Summary:** Binding agreement between...
> SEMANTIC_STRUCTURE_PRESERVED
PROJECT DOC-SURGEON
THE XML RECONSTRUCTOR
The Challenge: A legal firm had 50,000+ legacy MS Word documents from the 2000s. They were riddled with XML corruption that caused standard Python parsers to panic. The mission? Convert them all to clean Markdown for a RAG knowledge base.
The Architecture: A fault-tolerant conversion pipeline. I bypassed the standard python-docx library and went straight for the XML guts using Pandoc with custom Lua filters to perform "tree surgery" on broken tags.
- Speed: Processes 1,000 documents per minute via multiprocessing.
- Structure Preservation: Keeps headers, lists, and tables intact while stripping garbage styling.
- Universal Format: Outputs semantic Markdown that is instantly readable by any LLM.
PROJECT OMEGA
ENTERPRISE KNOWLEDGE-CORE
The Challenge: Clients needed to query internal PDFs quickly, but standard AI tools hallucinated facts and couldn't access private files. They needed a "Corporate Brain" that only spoke the truth.
The Architecture: A precision RAG pipeline. I orchestrated LangChain to chunk thousands of documents and index them in ChromaDB. When a user asks a question, the system retrieves the exact source paragraphs and forces GPT-4o to answer only using that evidence.
- Zero Hallucinations: Grounds every answer in retrieved citations. No creative fiction.
- Instant Recall: Reduces research time by 90%, finding needles in 10,000-page haystacks instantly.
- Hybrid Search: Combines semantic understanding (vectors) with keyword precision.
Visual Evidence
Production workflows and interfaces running in the wild.